AI摘要介绍
壹联网络推出企业级多商户发卡系统源码预售,售价488元。系统集开店、收款、发货、风控与营销于一体,支持多商户入驻独立经营,涵盖多模态数字商品与三级分销功能,旨在为数字商品及虚拟权益业务提供一站式解决方案。
源码预售价 ¥488(预计 20 号发布)
企业级多商户发卡系统,开店、收款、发货、风控、营销一站式搞定。支持多商户入驻独立店铺经营,全流程自动化高效省心,风控投诉联动保障交易安全,内置丰富营销工具助力业绩增长。
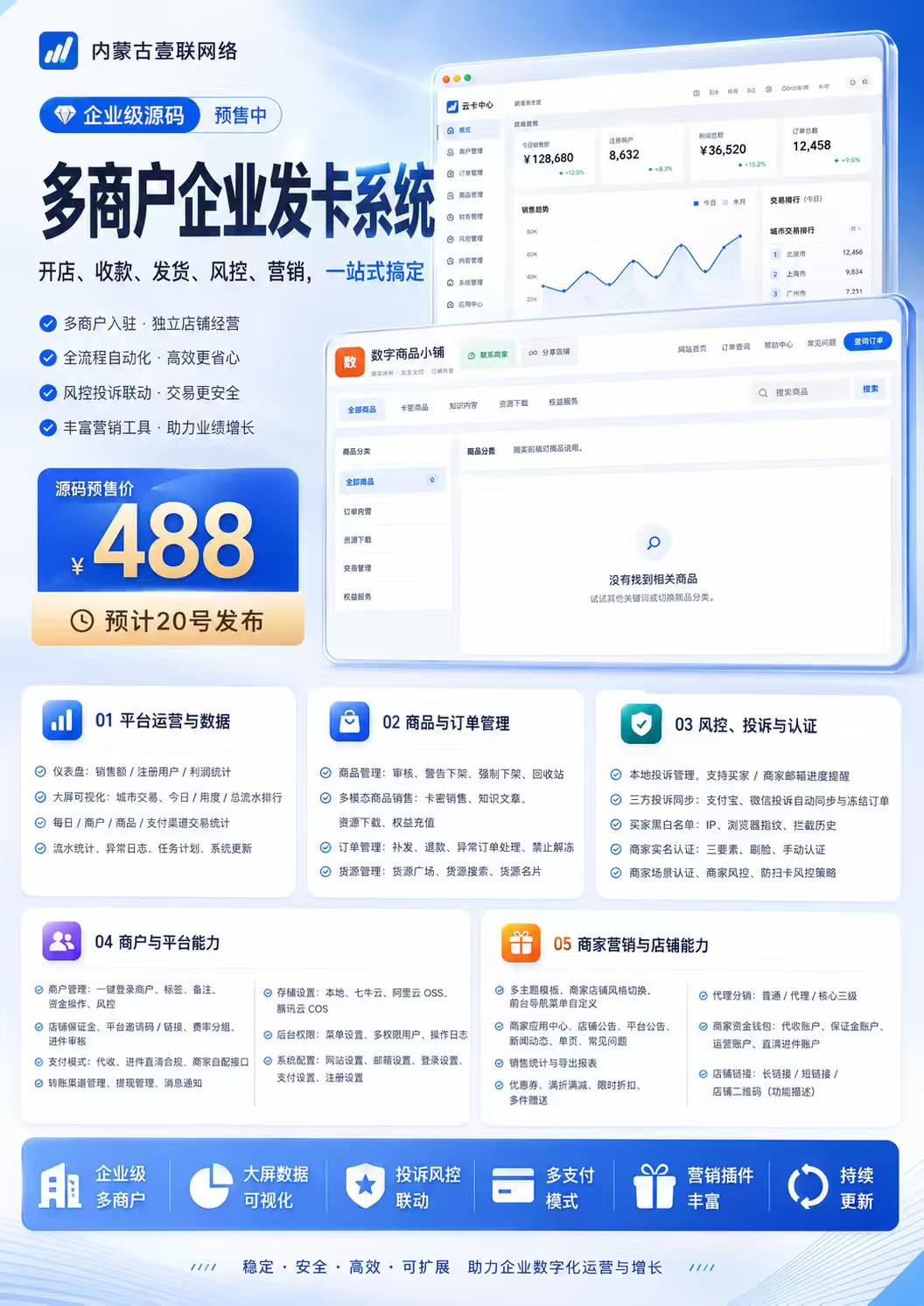
核心亮点
- 平台运营与数据:销售/注册/利润仪表盘,城市交易大屏可视化,每日、商户、商品、支付渠道流水统计。
- 商品与订单管理:卡密销售、知识文章、资源下载、权益充值等多模态商品,支持补发、退款与异常订单处理。
- 风控、投诉与认证:本地投诉管理、支付宝与微信投诉同步冻结、买家黑白名单、商家实名认证。
- 商户与平台能力:一键登录商户、店铺保证金、代收与进件直清模式、转账渠道与提现管理。
- 商家营销与店铺:多主题模板、优惠券、满减满折、限时折扣、普通/代理/核心三级分销。
- 存储与扩展:支持本地、七牛云、阿里云 OSS、腾讯云 COS,多支付模式灵活接入,持续更新。
适合谁购买
适合数字商品、卡密、虚拟权益类业务的创业者与企业;适合需要多商户入驻模式的平台运营方,以及希望快速搭建企业级发卡商城的团队。
购买说明
该产品为企业级源码预售,预计 20 号发布。购买前请确认交付时间、支付渠道进件要求、部署环境、商业授权和售后范围;源码持续更新,提供部署支持与运营级文档。